Results
With a new and improved workflow, the Portside team is now able to efficiently draft, revise and schedule videos and articles for their readers.
Since we launched the redesign in February 2018, portside.org has seen a 39% increase in users visiting the site, 23% increase in pageviews, 13% increase in session duration, and a complementary 11% decrease in bounce rate. This is all in spite of Facebook’s algorithm changes which severely hurt Portside and other independent publishers.
We continue to work with Portside to monitor the site’s performance, finding additional ways to improve the site and contribute to the independent, left media that is so critical in these times.
Mauricio Dinarte is a passionate Drupal developer, consultant, and trainer with over 10 years of web development experience. After completing his BS in Computer Science, graduating with the highest GPA among 181 students, he completed a Masters in Business Administration.
Mauricio started his Drupal journey in 2011 and fell in love with Drupal right away. Through the years, he has worked on projects of large scale playing different roles such as site builder, themer, module developer, and project manager. He has great experience leveraging various core and contrib APIs, using and customizing Drupal distributions like Open Outreach and OpenChurch, as well as creating custom installation profiles and distributions. He brews top shelf modules into elegant solutions. Views, Context, Display Suite, Panels, Feeds, OpenLayers, Features, and other modules are some of the ingredients. Drush is his ally to speed up development and manage workflows among different environments.
In addition to his technical skills, Mauricio is deeply involved in the Drupal community. He is the Nicaraguan community lead, where he regularly organizes and presents on Global Training Days, Global Sprint Weekends, and recurrent meetups. He also mentors new contributors as part of the Core Office Hours program. He has contributed Spanish translations, patches to core and contributed modules, and volunteered in various Drupal events.
Drupal is awesome, but every now and then one should get off the island™. Mauricio has also worked with Sencha Ext.JS and Sencha Touch for desktop and mobile application development.
He starves for new knowledge and loves to share what he has learned. In his free time, he enjoys reading.
Find me on Twitter at @dinarcon.
Agaric makes websites and applications that matter. We provide development services, training, and consulting to help define and meet your needs.
Goal
The most power possible for all people over our own lives.
Building blocks of freedom
- Free software
- Cooperative platforms
- Solidarity economy (examples: Ujima Boston, Cooperation Jackson)
- Personal power (ask Micky)
Power is coordination
“Knowledge is not power,” said Mariame Kaba (prisonculture), who knows a thing or two about it as a longtime organizer focusing on ending violence, dismantling the prison industrial complex, practicing transformative justice, and supporting youth leadership development.
Power is organization.
Ben tends to fixate on the injustices caused by an organized, unaccountable minority making decisions affecting a much larger but unorganized majority, but there are plenty of problems that have nothing or little to do with the problem of concentrated benefit and distributed cost. They're just still problems because we, society, hasn't gotten our act together. Traffic jams affect millions of people who, while mostly not in the 1% of income or wealth, are easily in the top couple quintiles.
Coordination requires not doing everything oneself
Ben notes: I strongly believes that we, people generally, need to have the ultimate say in the things that affect our lives, including our own workplaces, our Internet connection, our home water supply, mediating platforms like Facebook and Google, and our medical care.
That does not mean I or anyone else wants to be micromanaging my coworkers, laying cables and arguing protocols, inspecting plumbing, reviewing commits and moderating posts, and ordering doctors and nurses around.
Even various approaches to direct democracy don't mean people do all the work directly. But how can we be the ultimate decision-makers in so many aspects of society?
"The market" is attractive here: vote with your money.
A regular systematic redistribution of wealth could make that a feasible answer, but for now it means a certain few dozen people have more decision-making power than a few billion people.
So we need to try some other way of delegating authority.
On the problem of self-selected leaders
The major problem — one of the major problems, for there are several — one of the many major problems with governing people is that of whom you get to do it; or rather of who manages to get people to let them do it to them.
To summarize: it is a well-known fact that those people who must want to rule people are, ipso facto, those least suited to do it. To summarize the summary: anyone who is capable of getting themselves made President should on no account be allowed to do the job. To summarize the summary of the summary: people are a problem.
Chapter 28, The Restaurant at the End of the Universe, by Douglas Adams in the Hitchhiker's Guide to the Galaxy series.
Solutions to the problem of self-selected leaders
- Citizens' Assembly: "a representative group of citizens who are selected at random from the population to learn about, deliberate upon, and make recommendations in relation to a particular issue or set of issues. Other similar bodies have operated in parts of Canada – notably British Columbia and Ontario – and there is a citizens’ assembly currently operating in Ireland. This website [citizensassembly.co.uk] draws together experiences of Citizens Assemblies in the UK."
Democracy at scale: Historically possible
almost everyone nowadays insists that participatory democracy, or social equality, can work in a small community or activist group, but cannot possibly ‘scale up’ to anything like a city, a region, or a nation-state. But the evidence before our eyes, if we choose to look at it, suggests the opposite. Egalitarian cities, even regional confederacies, are historically quite commonplace. Egalitarian families and households are not.
David Graeber and David Wengrow, "How to change the coures of human history (at least, the part that's already happened)" (2 March 2018) accessed 2018 December.
Tyranny of structurelessness
During the years in which the [open source] movement has been taking shape, a great emphasis has been placed on what are called leaderless, structureless groups as the main -- if not sole -- organizational form of the movement. The source of this idea was a natural reaction against the over-structured [corporations and universities] in which most of us found ourselves, and the inevitable control this gave others over our lives, and the continual elitism of the Left and similar groups among those who were supposedly fighting this overstructuredness.
The idea of "[openness/structurelessness]," however, has moved from a healthy counter to those tendencies to becoming a goddess in its own right. The idea is as little examined as the term is much used, but it has become an intrinsic and unquestioned part of [open source philosophy]. For the early development of the movement this did not much matter. It early defined its main goal, and its main method, as [writing working code and] consciousness-raising, and the "structureless" [open] group was an excellent means to this end. The looseness and informality of it encouraged participation in discussion, and its often supportive atmosphere elicited personal insight. If nothing more concrete than personal [itch-scratching and] insight ever resulted from these groups, that did not much matter, because their purpose did not really extend beyond this.
Jo Freeman (aka Joreen) famous essay The Tyranny of Structurelessness (with the references to the women's liberation movement replaced with references to free software).
See also Cathy Levine's response, "The Tyranny of Tyranny". An excerpt:
Contrary to the belief that lack of up-front structures lead to insidious, invisible structures based on elites, the absence of structures in small, mutual trust groups fights elitism on the basic level — the level of personal dynamics, at which the individual who counters insecurity with aggressive behaviour rules over the person whose insecurity maintains silence. The small personally involved group learns, first to recognise those stylistic differences, and then to appreciate and work with them; rather than trying to either ignore or annihilate differences in personal style, the small group learns to appreciate and utilise them, thus strengthening the personal power of each individual.
Related
Meritocracy
The word meritocracy comes from a political satire. It was never meant to be something we should aspire to. It was the opposite, actually, a warning about how we rationalize what we believe we've "earned". If that sentence doesn't seem to you applicable to the tech industry and our cyclical discussions about sexism, racism, and even occasionally classism,
... then read that blog post, "you keep using that word" (content warning: cuss words).
Rough consensus
Common in technical projects, a particular approach of "rough consensus"—a decision moves forward when all objections have been resolved in a way that everyone can live with or at least have been seriously considered and judged not to be showstoppers, whether or not anyone is still actively making the objection—is probably best described as the Internet Engineering Task Force's ideal in an informational document by Pete Resnick, On Consensus and Humming in the IETF.
Decision-making in Drupal
Drupal is not a democracy
The governance group itself, along with its assignment, is a product of the very power structure it's tasked with reworking. The task force was personally approved by the dictator for life. It reports to the dictator for life. Any decision on its recommendations will be made by the dictator for life.
Nedjo Rogers, Drupal and governance.
Governance group agrees
Having a BDFL model means loyalty, time, and attention is divided. There is often frustration as pressure for change and decisions reach an individual bottleneck. There is a strong feeling that any community change or action requires Dries’ approval before commencing let alone expanding. The project is bigger than one individual; it’s time to recognise that and place a community group at the center.
The Drupal Governance Task Force 2018 Proposal; see the issue posted for this in the Drupal Community Governance project.
Background reading
In addition to the works quoted above, here are some that informed our presentation.
Articles
- Drupal and governance
- Six principles for conversational transformation
- Drupal as a political act
- The dehumanizing myth of meritocracy
- Drupal's Governance
- Zapatista - Caracoles - Resistance and Autonomy
- Murray Bookchin and the Kurdish resistance
Books
- Collective Courage: A History of African American Cooperative Economic Thought and Practice, by Jessica Gordon Nembard
- Life and Ideas: The Anarchist Writings of Errico Malatesta
- The Anarchist Collectives: Workers’ Self-Management in the Spanish Revolution, 1936–1939 edited by Sam Dolgoff (full text online)
Other links of interest
Federated/P2P/decentralized services.
https://redecentralize.org
https://prism-break.org/en/all/
https://secushare.org/comparison
Projects:
https://p2pfoundation.net/ https://gnunet.org/en/
https://tox.chat/about.html
https://net2o.de
https://ipfs.io https://github.com/cjdelisle/cjdns




Those could be separated by a comma using CSS. For example, "By Clayton Dewey, Ben Melançon, David Valdez."
A more natural display, though, would be "By Clayton Dewey, Ben Melançon, and David Valdez." If, instead of three people, two people wrote the article (as is the case), we would want to display "By Clayton Dewey and Ben Melançon."
Before, a sitebuilder would have to abandon structured content for a text field which an editor would use instead. In other words, instead of using a reference field to display the authors (even if present on the edit form), the sitebuilder would add a regular text field for the content editor to write out the list in a more human-friendly way and that is what would be output, or the content editor would write the byline into the body field.
Now, displaying lists of structured content naturally is possible with the In Other Words module.
(More featureful listings are also possible with Twig templates, but that does not empower sitebuilders— it bogs down themers!)
For text list fields and entity reference fields, In Other Words provides the In Other Words: List field formatter. Its settings page looks like this:
The Challenge
Many teachers lack the skills and confidence to effectively integrate computer modeling and simulation into their science classrooms. Research studies show that it takes more than a single professional development workshop to build the necessary skill and confidence. Online communities have been proposed as a means to address this problem. Teachers with GUTS (Growing Up Thinking Scientifically) offers an engaging middle school curriculum and accompanying professional development for teachers.
Through the use of an online community of practice, Teachers with GUTS is able to support teachers in mitigating challenges, gaining expertise by providing additional training and resources, and providing answers to teachers; questions as they bring computational science experiences into their classrooms. To truly teach with GUTS, teachers needed a community they could turn to.
Social media platforms and existing online discussion forums were considered, but research showed that these platforms lacked the features specifically needed. Instead, they needed a platform tailored to their needs:
- Forum for topical discussions
- Resource library to share documents, videos, and code
- Events listing page
- Practice area for participating in monthly “challenges” or “work sessions”
Our Approach
Through our discovery work we specifically identified that a forum, resource library, practice space, and faceted search would provide teachers with support and resources and tools they need to teach the curricula with confidence. TWiG would then support the website with both drip and push marketing to promote the resources and encourage activity.
Resource Library
Project GUTS CS in Science curriculum is the heart of TWiG’s work. There are several learning modules as well as supporting documents such as rubrics and supplementary activities. We built the resource library that displayed the most recent additions front and center, while providing a faceted search option so teachers can drill down to specific resources.
We also took advantage of the collaborative spirit of the TWiG community by allowing teachers to submit their own resources. These resources are then reviewed by TWiG staff and published after review, revision if needed, and alignment with standards.
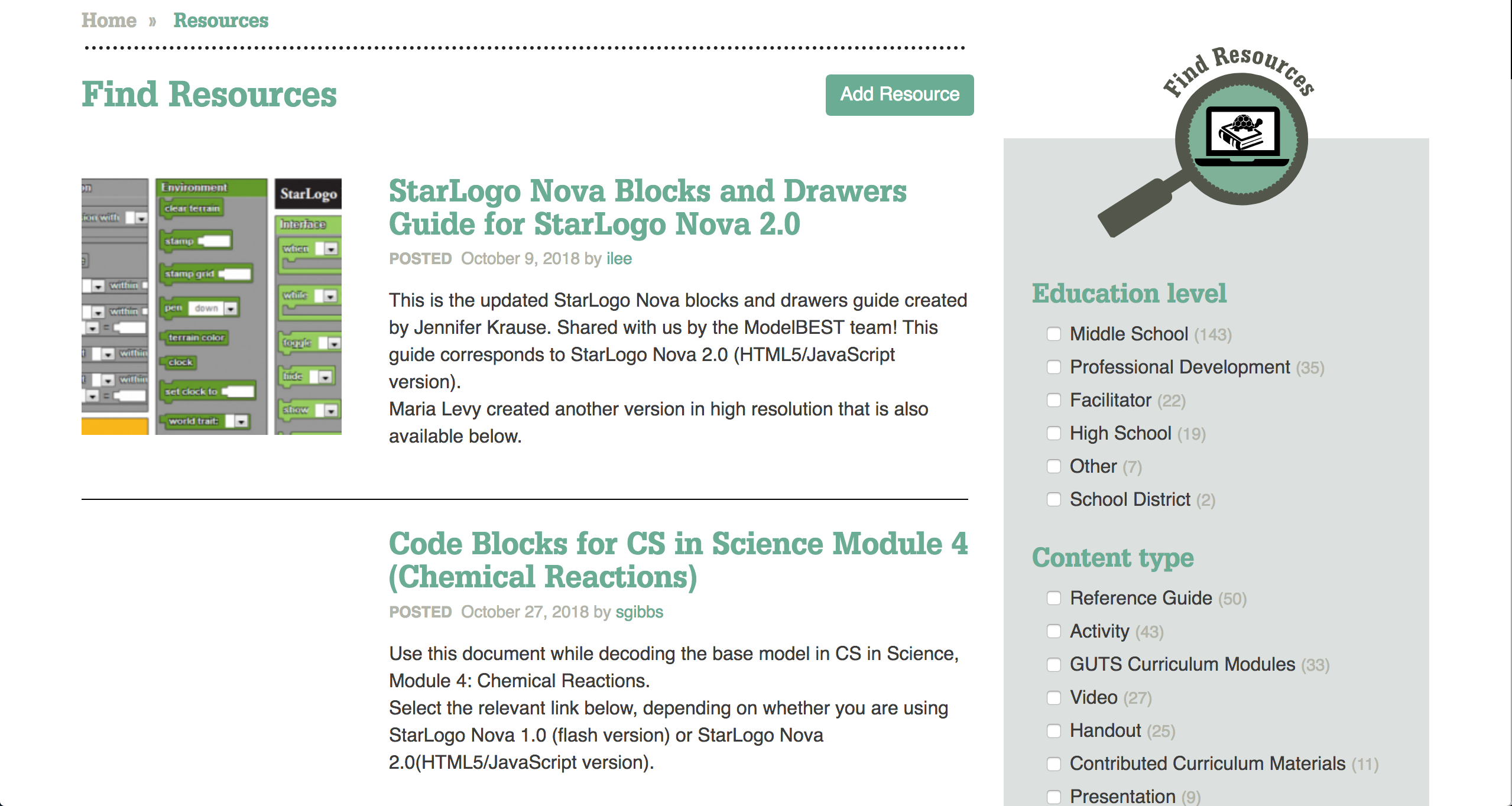 Faceted search allows teachers to find resources based on several criteria.
Faceted search allows teachers to find resources based on several criteria.
Forum
To support online discussion and peer assistance, we built a forum. We built off of Drupal Core’s Forum module and extended it to include an area accessible only to facilitators with a custom module.
We customized the forum further by disabling threaded comments, as that structure did not work well for the teachers using the site. However, in doing so we learned of a longstanding issue with Drupal and comments in which converting threaded comments to a flat structure risks deleting the nested comments. In response, we ported the Flat Comments module to Drupal 8.
Bookmarks
Even with faceted search and thoughtful categorization, the number of resources and discussions on the site can be overwhelming. We created a Drupal 8 version of the Backpack module that allows teachers to save pages to their “backpack.”
These backpacks can either be private or shared with other members. Curating specific lists is another way teachers can share knowledge with one another.
You can download and use the Backpack module on your Drupal site at https://github.com/agaric/bookmark
 Teachers can bookmark a resource or discussion for quick access in the future.
Teachers can bookmark a resource or discussion for quick access in the future.
Notifications
While a custom site was more advantageous than an email list or Facebook group, the reality is that most teachers’ daily routine does not include visiting teacherswithguts.org. In order to keep teachers engaged they needed a way to know when relevant activity was taking place.
We built a notification system, configurable by each teacher, so that they could be emailed about activity pertinent to their work. Teachers can choose to receive the following notifications:
- When a new article is posted
- When a new resource is posted
- When a new discussion is posted
- When a comment is made on a discussion
Additionally, teachers choose the day to be sent emails, as well as the frequency. This was all made possible by enhancing the Personal Digest and Comment Notify modules.
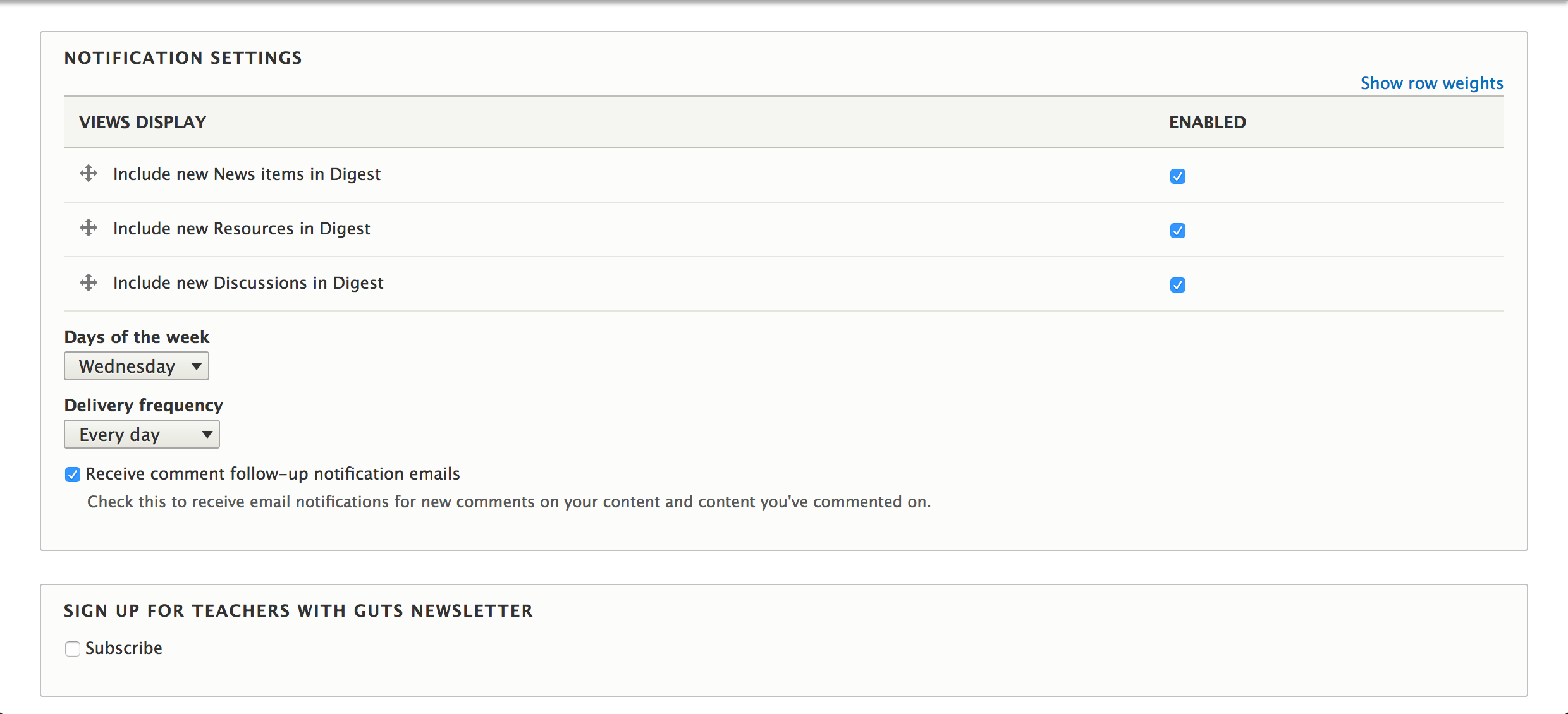 We enhanced the Personal Digest and Comment Notify modules to give users fine grained control over their notifications.
We enhanced the Personal Digest and Comment Notify modules to give users fine grained control over their notifications.
Member Directory
To build upon the networking happening in the forums, we made it easy for teachers to find one another based on shared on interests, experience and geography. Each teacher customizes their member profile with key information about themselves, their areas of expertise and the areas they wish to grow. We then surfaced that in a filterable search of members, helping teachers mentor one another.
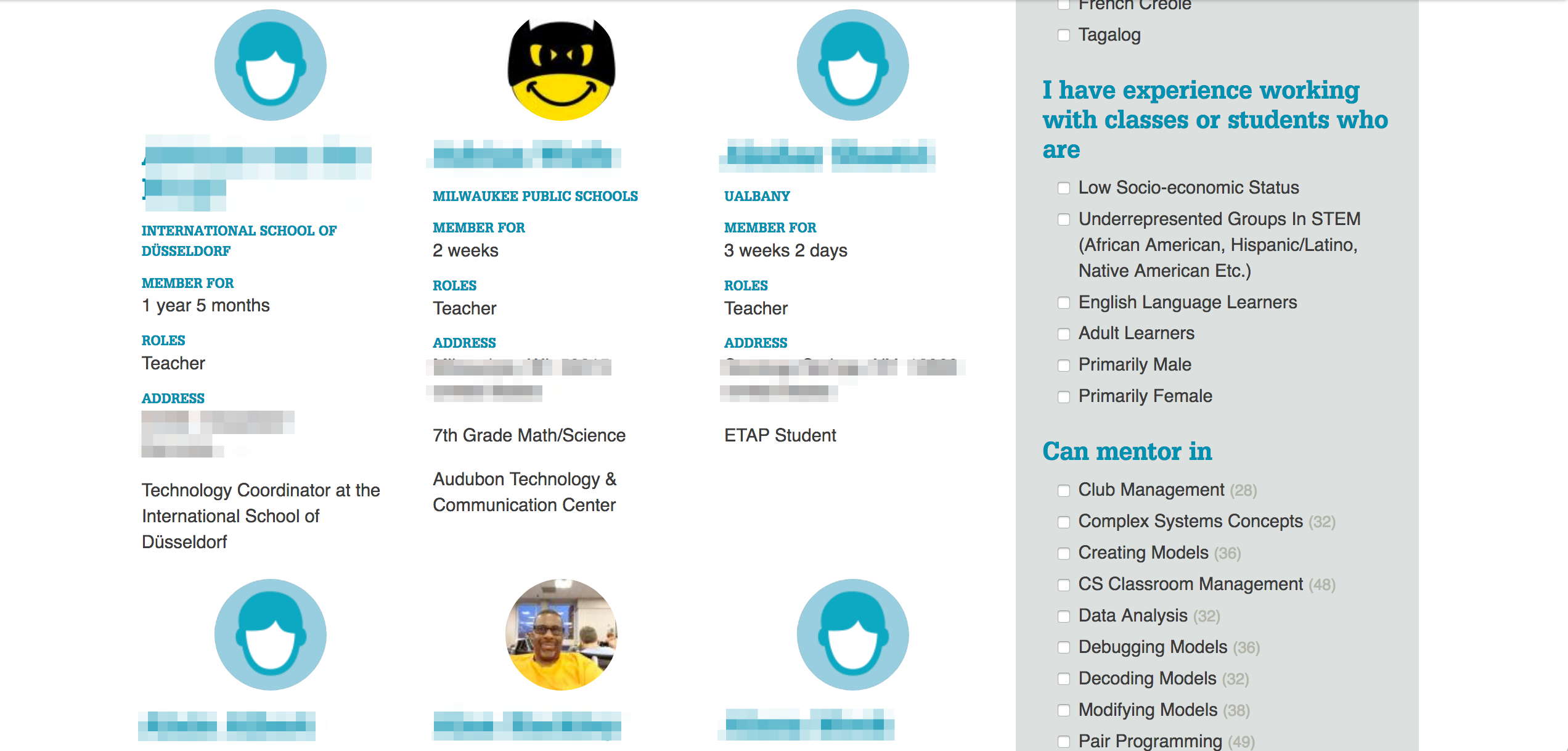 Members can easily find others with similar interests in the member directory.
Members can easily find others with similar interests in the member directory.
Results
With an onboarding process much improved from their previous site, plus the ability to bulk invite users, TWiG was able to sign up over 700 teachers when the site launched in 2016. We’ve continued to improve the site to increase participation and surface useful metrics for site administrators and researchers.
Former school teacher turned technologist, Clayton now applies his background in linguistics, community organizing and web development as a user experience architect for Agaric and co-founder of Drutopia.
Clayton has worked with universities, open source companies, tech diversity advocates, prison abolitionists, and others to translate their organizational goals into impactful digital tools with meaningful content.
Aside from content strategy and information architecture, Clayton also enjoys being a goofy dad and always appreciates a good paraprosdokian.
Worker owned cooperatives are businesses owned and controlled by the people who work in them. This is a collection of resources that will help you navigate the world of cooperatives and opportunities.
This list will continue to grow and connect with cooperative networks around the globe.
Boston area:
- WORC'N, the Worker-Owned and Run Cooperative Network of Greater Boston is a network of worker-owned cooperatives, co-op developers, and those seeking support to start worker cooperatives.
- Boston Center for Community Ownership
National/international:
- US Federation of Worker Cooperatives
- Democracy at Work aims to build a social movement for a new society whose productive enterprises (offices, factories, and stores) will mostly be Worker Self-Directed Enterprises (WSDEs), a true economic democracy.
- North American Technology Worker Cooperatives
- Tech Coop How To - .pdf
Find worker cooperatives:
- Member directory of the US Federation of Worker Cooperatives
- Find.coop (open directory of all types of coops)
- ica.coop (open directory of all types of coops)
- Drupal Worker Cooperative group and overall Drupal coop group. See in particular Wiki of worker coops and resources.
Legal resources
News articles about cooperatives:
Presentations and speakers:
Cooperative Resources:
Some great events happened in 2014 based around building cooperatives and collectives. These events should have videos online of the speakers and events: California Cooperative Conference and Chicago Freedom Summer

Find It
Program Locator and
Event Discovery platform
Search a curated directory of events
Filter results based on age, location, cost, activity, and schedule.
Benjamin lives and works to connect people, ideas, and resources so more awesome things happen.
A web developer well-established with Drupal and PHP, he has also been enjoying programming projects with Django and Python. His work with Agaric clients has included universities (MIT and Harvard University), corporations (Backupify and GenArts), and not-for-profit organizations (Partners In Health and National Institute for Children's Health Quality).
Benjamin tries to aid struggles for justice and liberty, or try not to do harm in the meantime. He is an organizer of the People Who Give a Damn, recognized as an incorporated entity by the IRS and the Commonwealth of Massachusetts charities division. He has also supported several artistic and philanthropic ventures and was a founding, elected director to the Amazing Things Arts Center in Framingham, Massachusetts.
He led 34 authors in writing the 1,100 page Definitive Guide to Drupal 7, but he is probably still best known in the Drupal community for posting things he finds to data.agaric.com where developers running into the same challenges find, if not answers, comfort that they are not alone.
You can get more (too much) of ben on a cooperatively-run part of the fediverse at @mlncn@social.coop.

Turning off links to entities that have been Rabbit Holed
in modern Drupal
Mostrar y Contar
Comparte lo que has aprendido. Vea lo que otros están haciendo.
Today we are going to learn how to migrate users into Drupal. The example code will be explained in two blog posts. In this one, we cover the migration of email, timezone, username, password, and status. In the next one, we will cover creation date, roles, and profile pictures. Several techniques will be implemented to ensure that the migrated data is valid. For example, making sure that usernames are not duplicated.
Although the example is standalone, we will build on many of the concepts that had already been covered in the series. For instance, a file migration is included to import images used as profile pictures. This topic has been explained in detail in a previous post, and the example code is pretty similar. Therefore, no explanation is provided about the file migration to keep the focus on the user migration. Feel free to read other posts in the series if you need a refresher.

Getting the code
You can get the full code example at https://github.com/dinarcon/ud_migrations The module to enable is UD users whose machine name is ud_migrations_users. The two migrations to execute are udm_user_pictures and udm_users. Notice that both migrations belong to the same module. Refer to this article to learn where the module should be placed.
The example assumes Drupal was installed using the standard installation profile. Particularly, we depend on a Picture (user_picture) image field attached to the user entity. The word in parenthesis represents the machine name of the image field.
The explanation below is only for the user migration. It depends on a file migration to get the profile pictures. One motivation to have two migrations is for the images to be deleted if the file migration is rolled back. Note that other techniques exist for migrating images without having to create a separate migration. We have covered two of them in the articles about subfields and constants and pseudofields.
Understanding the source
It is very important to understand the format of your source data. This will guide the transformation process required to produce the expected destination format. For this example, it is assumed that the legacy system from which users are being imported did not have unique usernames. Emails were used to uniquely identify users, but that is not desired in the new Drupal site. Instead, a username will be created from a public_name source column. Special measures will be taken to prevent duplication as Drupal usernames must be unique. Two more things to consider. First, source passwords are provided in plain text (never do this!). Second, some elements might be missing in the source like roles and profile picture. The following snippet shows a sample record for the source section:
source:
plugin: embedded_data
data_rows:
- legacy_id: 101
public_name: 'Michele'
user_email: 'micky@example.com'
timezone: 'America/New_York'
user_password: 'totally insecure password 1'
user_status: 'active'
member_since: 'January 1, 2011'
user_roles: 'forum moderator, forum admin'
user_photo: 'P01'
ids:
legacy_id:
type: integerConfiguring the destination and dependencies
The destination section specifies that user is the target entity. When that is the case, you can set an optional md5_passwords configuration. If it is set to true, the system will take an MD5 hashed password and convert it to the encryption algorithm that Drupal uses. For more information password migrations refer to these articles for basic and advanced use cases. To migrate the profile pictures, a separate migration is created. The dependency of user on file is added explicitly. Refer to these articles more information on migrating images and files and setting dependencies. The following code snippet shows how the destination and dependencies are set:
destination:
plugin: 'entity:user'
md5_passwords: true
migration_dependencies:
required:
- udm_user_pictures
optional: []Processing the fields
The interesting part of a user migration is the field mapping. The specific transformation will depend on your source, but some arguably complex cases will be addressed in the example. Let’s start with the basics: verbatim copies from source to destination. The following snippet shows three mappings:
mail: user_email
init: user_email
timezone: user_timezoneThe mail, init, and timezone entity properties are copied directly from the source. Both mail and init are email addresses. The difference is that mail stores the current email, while init stores the one used when the account was first created. The former might change if the user updates its profile, while the latter will never change. The timezone needs to be a string taken from a specific set of values. Refer to this page for a list of supported timezones.
name:
- plugin: machine_name
source: public_name
- plugin: make_unique_entity_field
entity_type: user
field: name
postfix: _The name, entity property stores the username. This has to be unique in the system. If the source data contained a unique value for each record, it could be used to set the username. None of the unique source columns (eg., legacy_id) is suitable to be used as username. Therefore, extra processing is needed. The machine_name plugin converts the public_name source column into transliterated string with some restrictions: any character that is not a number or letter will be converted to an underscore. The transformed value is sent to the make_unique_entity_field. This plugin makes sure its input value is not repeated in the whole system for a particular entity field. In this example, the username will be unique. The plugin is configured indicating which entity type and field (property) you want to check. If an equal value already exists, a new one is created appending what you define as postfix plus a number. In this example, there are two records with public_name set to Benjamin. Eventually, the usernames produced by running the process plugins chain will be: benjamin and benjamin_1.
process:
pass:
plugin: callback
callable: md5
source: user_password
destination:
plugin: 'entity:user'
md5_passwords: trueThe pass, entity property stores the user’s password. In this example, the source provides the passwords in plain text. Needless to say, that is a terrible idea. But let’s work with it for now. Drupal uses portable PHP password hashes implemented by PhpassHashedPassword. Understanding the details of how Drupal converts one algorithm to another will be left as an exercise for the curious reader. In this example, we are going to take advantage of a feature provided by the migrate API to automatically convert MD5 hashes to the algorithm used by Drupal. The callback plugin is configured to use the md5 PHP function to convert the plain text password into a hashed version. The last part of the puzzle is set, in the process section, the md5_passwords configuration to true. This will take care of converting the already md5-hashed password to the value expected by Drupal.
Note: MD5-hash passwords are insecure. In the example, the password is encrypted with MD5 as an intermediate step only. Drupal uses other algorithms to store passwords securely.
status:
plugin: static_map
source: user_status
map:
inactive: 0
active: 1The status, entity property stores whether a user is active or blocked from the system. The source user_status values are strings, but Drupal stores this data as a boolean. A value of zero (0) indicates that the user is blocked while a value of one (1) indicates that it is active. The static_map plugin is used to manually map the values from source to destination. This plugin expects a map configuration containing an array of key-value mappings. The value from the source is on the left. The value expected by Drupal is on the right.
Technical note: Booleans are true or false values. Even though Drupal treats the status property as a boolean, it is internally stored as a tiny int in the database. That is why the numbers zero or one are used in the example. For this particular case, using a number or a boolean value on the right side of the mapping produces the same result.
In the next blog post, we will continue with the user migration. Particularly, we will explain how to migrate the user creation time, roles, and profile pictures.
What did you learn in today’s blog post? Have you migrated user passwords before, either in plain text or hashed? Did you know how to prevent duplicates for values that need to be unique in the system? Were you aware of the plugin that allows you to manually map values from source to destination? Please share your answers in the comments. Also, I would be grateful if you shared this blog post with others.
Next: Migrating users into Drupal - Part 2
This blog post series, cross-posted at UnderstandDrupal.com as well as here on Agaric.coop, is made possible thanks to these generous sponsors. Contact Understand Drupal if your organization would like to support this documentation project, whether it is the migration series or other topics.
