We have already covered two of many ways to migrate images into Drupal. One example allows you to set the image subfields manually. The other example uses a process plugin that accomplishes the same result using plugin configuration options. Although valid ways to migrate images, these approaches have an important limitation. The files and images are not removed from the system upon rollback. In the previous blog post, we talked further about this topic. Today, we are going to perform an image migration that will clear after itself when it is rolled back. Note that in Drupal images are a special case of files. Even though the example will migrate images, the same approach can be used to import any type of file. This migration will also serve as the basis for explaining migration dependencies in the next blog post.

File entity migrate destination
All the examples so far have been about creating nodes. The migrate API is a full ETL framework able to write to different destinations. In the case of Drupal, the target can be other content entities like files, users, taxonomy terms, comments, etc. Writing to content entities is straightforward. For example, to migrate into files, the process section is configured like this:
destination:
plugin: 'entity:file'You use a plugin whose name is entity: followed by the machine name of your target entity. In this case file. Other possible values are user, taxonomy_term, and comment. Remember that each migration definition file can only write to one destination.
Source section definition
The source of a migration is independent of its destination. The following code snippet shows the source definition for the image migration example:
source:
constants:
SOURCE_DOMAIN: 'https://agaric.coop'
DRUPAL_FILE_DIRECTORY: 'public://portrait/'
plugin: embedded_data
data_rows:
- photo_id: 'P01'
photo_url: 'sites/default/files/2018-12/micky-cropped.jpg'
- photo_id: 'P02'
photo_url: ''
- photo_id: 'P03'
photo_url: 'sites/default/files/pictures/picture-94-1480090110.jpg'
- photo_id: 'P04'
photo_url: 'sites/default/files/2019-01/clayton-profile-medium.jpeg'
ids:
photo_id:
type: stringNote that the source contains relative paths to the images. Eventually, we will need an absolute path to them. Therefore, the SOURCE_DOMAIN constant is created to assemble the absolute path in the process pipeline. Also, note that one of the rows contains an empty photo_url. No file can be created without a proper URL. In the process section we will accommodate for this. An alternative could be to filter out invalid data in a source clean up operation before executing the migration.
Another important thing to note is that the row identifier photo_id is of type string. You need to explicitly tell the system the name and type of the identifiers you want to use. The configuration for this varies slightly from one source plugin to another. For the embedded_data plugin, you do it using the ids configuration key. It is possible to have more than one source column as identifier. For example, if the combination of two columns (e.g. name and date of birth) are required to uniquely identify each element (e.g. person) in the source.
You can get the full code example at https://github.com/dinarcon/ud_migrations The module to enable is UD migration dependencies introduction whose machine name is ud_migrations_dependencies_intro. The migration to run is udm_dependencies_intro_image. Refer to this article to learn where the module should be placed.
Process section definition
The fields to map in the process section will depend on the target. For files and images, only one entity property is required: uri. Its value should be set to the file path within Drupal using stream wrappers. In this example, the public stream (public://) is used to store the images in a location that is publicly accessible by any visitor to the site. If the file was already in the system and we knew the path the whole process section for this migration could be reduced to two lines:
process:
uri: source_column_file_uriThat is rarely the case though. Fortunately, there are many process plugins that allow you to transform the available data. When combined with constants and pseudofields, you can come up with creative solutions to produce the format expected by your destination.
Skipping invalid records
The source for this migration contains one record that lacks the URL to the photo. No image can be imported without a valid path. Let’s accommodate for this. In the same step, a pseudofield will be created to extract the name of the file out of its path.
psf_destination_filename:
- plugin: callback
callable: basename
source: photo_url
- plugin: skip_on_empty
method: row
message: 'Cannot import empty image filename.'The psf_destination_filename pseudofield uses the callback plugin to derive the filename from the relative path to the image. This is accomplished using the basename PHP function. Also, taking advantage of plugin chaining, the system is instructed to skip process the row if no filename could be obtained. For example, because an empty source value was provided. This is done by the skip_on_empty which is also configured log a message to indicate what happened. In this case, the message is hardcoded. You can make it dynamic to include the ID of the row that was skipped using other process plugins. This is left as an exercise to the curious reader. Feel free to share your answer in the comments below.
Tip: To read the messages log during any migration, execute the following Drush command: drush migrate:messages [migration-id].
Creating the destination URI
The next step is to create the location where the file is going to be saved in the system. For this, the psf_destination_full_path pseudofield is used to concatenate the value of a constant defined in the source and the file named obtained in the previous step. As explained before, order is important when using pseudofields as part of the migrate process pipeline. The following snippet shows how to do it:
psf_destination_full_path:
- plugin: concat
source:
- constants/DRUPAL_FILE_DIRECTORY
- '@psf_destination_filename'
- plugin: urlencodeThe end result of this operation would be something like public://portrait/micky-cropped.jpg. The URI specifies that the image should be stored inside a portrait subdirectory inside Drupal’s public file system. Copying files to specific subdirectories is not required, but it helps with file organizations. Also, some hosting providers might impose limitations on the number of files per directory. Specifying subdirectories for your file migrations is a recommended practice.
Also note that after the URI is created, it gets encoded using the urlencode plugin. This will replace special characters to an equivalent string literal. For example, é and ç will be converted to %C3%A9 and %C3%A7 respectively. Space characters will be changed to %20. The end result is an equivalent URI that can be used inside Drupal, as part of an email, or via another medium. Always encode any URI when working with Drupal migrations.
Creating the source URI
The next step is to create assemble an absolute path for the source image. For this, you concatenate the domain stored in a source constant and the image relative path stored in a source column. The following snippet shows how to do it:
psf_source_image_path:
- plugin: concat
delimiter: '/'
source:
- constants/SOURCE_DOMAIN
- photo_url
- plugin: urlencodeThe end result of this operation will be something like https://agaric.coop/sites/default/files/2018-12/micky-cropped.jpg. Note that the concat and urlencode plugins are used just like in the previous step. A subtle difference is that a delimiter is specifying in the concatenation step. This is because, contrary to the DRUPAL_FILE_DIRECTORY constant, the SOURCE_DOMAIN constant does not end with a slash (/). This was done intentionally to highlight two things. First, it is important to understand your source data. Second, you can transform it as needed by using various process plugins.
Copying the image file to Drupal
Only two tasks remain to complete this image migration: download the image and assign the uri property of the file entity. Luckily, both steps can be accomplished at the same time using the file_copy plugin. The following snippet shows how to do it:
uri:
plugin: file_copy
source:
- '@psf_source_image_path'
- '@psf_destination_full_path'
file_exists: 'rename'
move: FALSE
The source configuration of file_copy plugin expects an array of two values: the URI to copy the file from and the URI to copy the file to. Optionally, you can specify what happens if a file with the same name exists in the destination directory. In this case, we are instructing the system to rename the file to prevent name clashes. The way this is done is appending the string _X to the filename and before the file extension. The X is a number starting with zero (0) that keeps incrementing until the filename is unique. The move flag is also optional. If set to TRUE it tells the system that the file should be moved instead of copied. As you can guess, Drupal does not have access to the file system in the remote server. The configuration option is shown for completeness, but does not have any effect in this example.
In addition to downloading the image and place it inside Drupal’s file system, the file_copy also returns the destination URI. That is why this plugin can be used to assign the uri destination property. And that’s it, you have successfully imported images into Drupal! Clever use of the process pipeline, isn’t it? ;-)
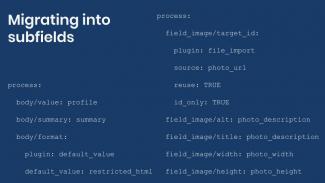
One important thing to note is an image’s alternative text, title, width, and height are not associated with the file entity. That information is actually stored in a field of type image. This will be illustrated in the next article. To reiterate, the same approach to migrate images can be used to migrate any file type.
Technical note: The file entity contains other properties you can write to. For a list of available options check the baseFieldDefinitions() method of the File class defining the entity. Note that more properties can be available up in the class hierarchy. Also, this entity does not have multiple bundles like the node entity does.
What did you learn in today’s blog post? Had you created file migrations before? If so, had you followed a different approach? Did you know that you can do complex data transformations using process plugins? Did you know you can skip the processing of a row if the required data is not available? Please share your answers in the comments. Also, I would be grateful if you shared this blog post with your colleagues.
Next: Introduction to migration dependencies in Drupal
This blog post series, cross-posted at UnderstandDrupal.com as well as here on Agaric.coop, is made possible thanks to these generous sponsors. Contact Understand Drupal if your organization would like to support this documentation project, whether it is the migration series or other topics.


{kind=link}
Comments
2020 June 03
Don Richards
Wow, this is a great…
Wow, this is a great breakdown. Thanks for this
Add new comment